SiteTest.ai launches a free AI Visibility Checker for ChatGPT, Perplexity & Gemini
SiteTest.ai launches a free AI Visibility Checker for ChatGPT, Perplexity & Gemini
A new tool aimed at SEO teams and indie devs goes live: sitetest.ai runs a 168-point GEO audit of your site against the major AI search surfaces — ChatGPT, Perplexity, Google AI Overviews, Gemini and Bing Copilot — and ships copy-paste code fixes, not just a vibes report.
Why it matters
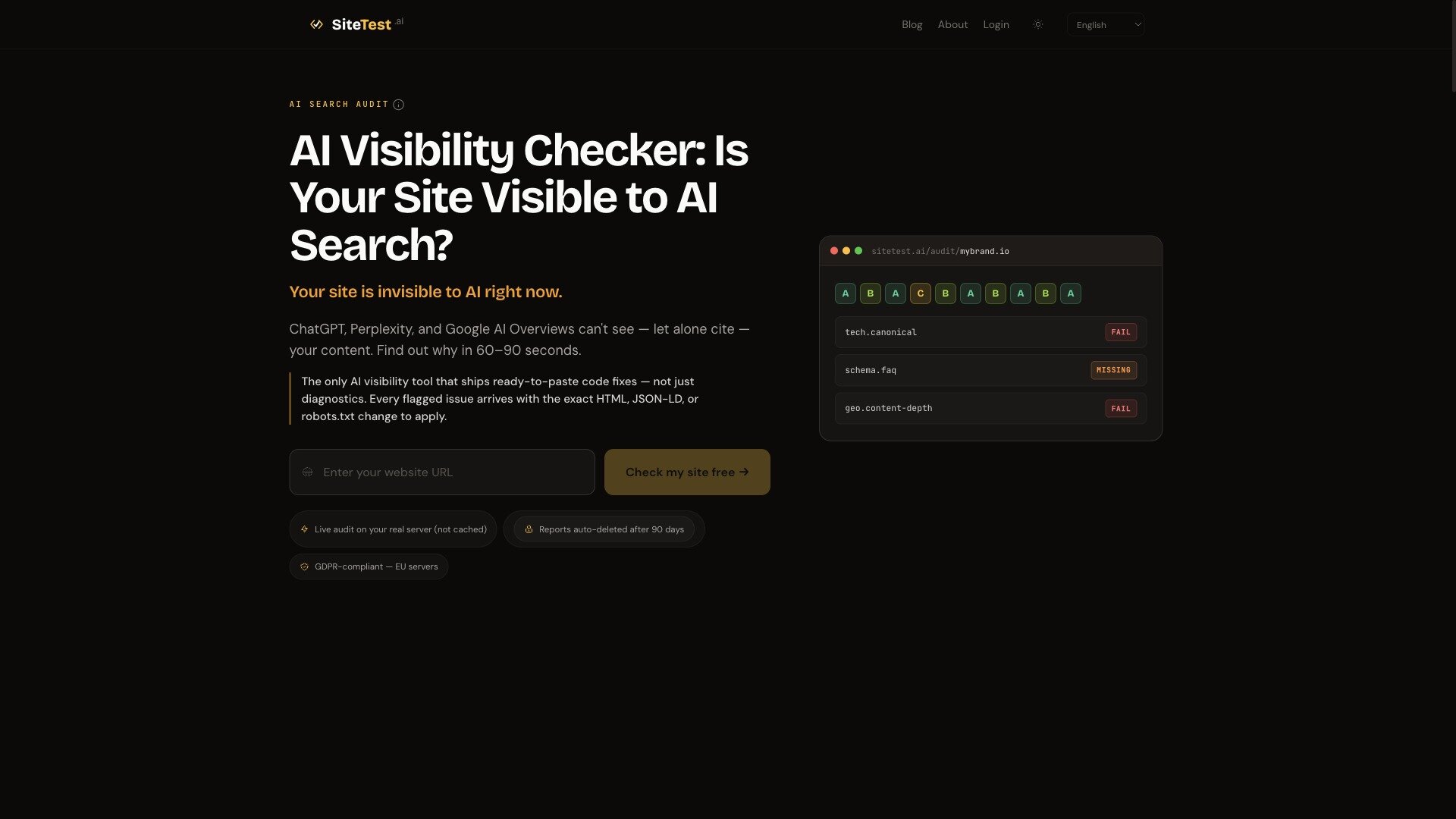
Most "AI visibility" checkers count keywords. SiteTest probes the actual AI crawlers (GPTBot, OAI-SearchBot, ChatGPT-User, PerplexityBot, Google-Extended, bingbot) on your real server and returns an A–F grade per engine. You see exactly where you are blocked — robots.txt, missing schema, JS-only rendering — and which platform-specific fix moves the needle.
What it does
- 168 checks across 10 categories — technical, on-page, content, performance, schema, security, accessibility, images, GEO, frontend.
- Per-engine scoring — separate readiness score for each AI surface, not one aggregate index.
- Brand-mention scanner — queries ChatGPT, Perplexity and Gemini for your brand, founder name, and product terms; logs whether you appear and how you are framed.
- Developer brief — exportable report with ready-to-ship HTML, JSON-LD and robots.txt fixes you can hand directly to engineering.
Pricing
Free tier covers the full audit (no signup, no card). Paid tiers ($4.99 / $24.99 one-time, no subscription) add the detailed developer brief, re-audits, and pro extensions. Pricing is intentionally low — closer to a one-time tool than to an SEO subscription.
Stack
Nuxt 3.21 with SSR and seven locales (en/uk/de/es/uz/kk/ru). The blog ships seven cornerstone articles on AI Search Engine Optimization, GEO and llms.txt, each translated into all seven languages. Backend: PostgreSQL + Redis + BullMQ for the audit queue, DeepSeek as the primary AI model with GPT-4.1-mini fallback.
Why this is interesting
AI search is fragmented. ChatGPT cites different sources than Perplexity. Gemini ranks differently from Bing Copilot. Most existing tools collapse this into one number. SiteTest treats each engine as a first-class target — which is closer to how the discipline actually plays out in 2026.
For SEO pros, the 168-point audit replaces a half-day manual checklist. For founders shipping a v1 site, it is the cheapest sanity check you can run before launch.
👉 Try it: https://sitetest.ai
👀 See Also

Visual Studio 2022 Extension Adds Native Ollama Integration for Local LLMs
A free extension for Visual Studio 2022 connects directly to local Ollama endpoints, enabling private AI coding assistance without switching between tools. It supports models like DeepSeek and Llama 3 with cloud fallback options.

Zap Code: AI Code Generator That Teaches Kids Real HTML/CSS/JS
Zap Code generates working HTML, CSS, and JavaScript from plain English descriptions for kids ages 8-16. It offers three interaction modes and runs in a sandboxed iframe with a progressive complexity engine.

OpenClaw Benchmark Shows Qwen3.5:27B Outperforms Other Local LLMs for Agent Tasks
A benchmark of 7 local LLMs on 22 real agent tasks using OpenClaw found qwen3.5:27b-q4_K_M scored 59.4%, while the runner-up qwen3.5:35b scored only 23.2%. Most models couldn't find basic tools like email functions.

Practical Findings from 11 Multi-Agent Software Builds Without Programmatic Scaffolding
Analysis of 11 autonomous multi-agent builds shows scope enforcement works mechanically (20/20 success) not via prompts (0/20), orchestration costs are dominated by memory re-ingestion (~95% of input spend), and worker model capability creates 9.8x throughput gaps.