pop-pay MCP server adds payment guardrails for Claude Code agents

pop-pay is an MCP server designed specifically for Claude Code users who need their AI agents to handle purchases autonomously without exposing actual credit card numbers. The tool addresses security concerns like hallucination loops, prompt injections, or bad tool calls that could lead to card extraction or unauthorized charges.
How it works
Setup involves three steps:
- Run
pop-launch— starts Chrome with CDP enabled and prints the exactclaude mcp addcommands for your machine - Add the pop-pay MCP server and Playwright MCP (both in one step)
- Add a short block to your
CLAUDE.md
When Claude reaches a checkout page, it calls request_virtual_card(). pop-pay evaluates the intent against your policy, and if approved, injects the card credentials directly into the payment iframe via CDP. Claude only receives a masked confirmation (like ****-****-****-4242) — the raw PAN never enters the context window.
Security features
Security hardening in versions v0.6.0 through v0.6.4 includes:
- Run
pop-init-vault— encrypts your card credentials into~/.config/pop-pay/vault.enc(one-time setup) - Credentials are stored in an AES-256-GCM encrypted vault — no plaintext
.env - The PyPI build compiles the key derivation salt into a Cython extension; the salt never exists as a Python object — only the final derived key does
- SQLite never stores raw card numbers or CVV
- An injection-time TOCTOU guard prevents redirect-to-attacker attacks between approval and injection
Red team testing revealed and fixed three issues: a get_compiled_salt() function leaking the compiled salt (fixed in v0.6.1), strings scanning revealing plaintext salt (patched with XOR obfuscation in v0.6.2), and a downgrade attack path where an agent could delete the .so and force re-encryption with the public salt (blocked by a tamper-evident .vault_mode marker in v0.6.4). Current release is v0.6.17.
Two-layer guardrail system
The system uses two layers of protection:
- Layer 1 (always on): Keyword + pattern engine — catches hallucination loops, prompt injection attempts in the reasoning payload, phishing URLs. Zero API cost, runs locally.
- Layer 2 (optional): LLM semantic evaluation — for fuzzy cases. Uses any OpenAI-compatible endpoint including local models. Layer 2 only runs if Layer 1 passes, avoiding token costs on obvious rejections.
Policy configuration
Users define their own policies with environment variables:
POP_ALLOWED_CATEGORIES=["aws", "github", "stripe"]
POP_MAX_PER_TX=50.0
POP_MAX_DAILY=200.0If Claude tries to buy something outside the allowed list — even with a convincing-sounding reason — it gets blocked.
The developer is seeking feedback from anyone building with Claude Code + MCP, specifically about whether the CDP injection approach holds up on actual sites and what checkout flows might break this kind of DOM injection.
📖 Read the full source: r/ClaudeAI
👀 See Also
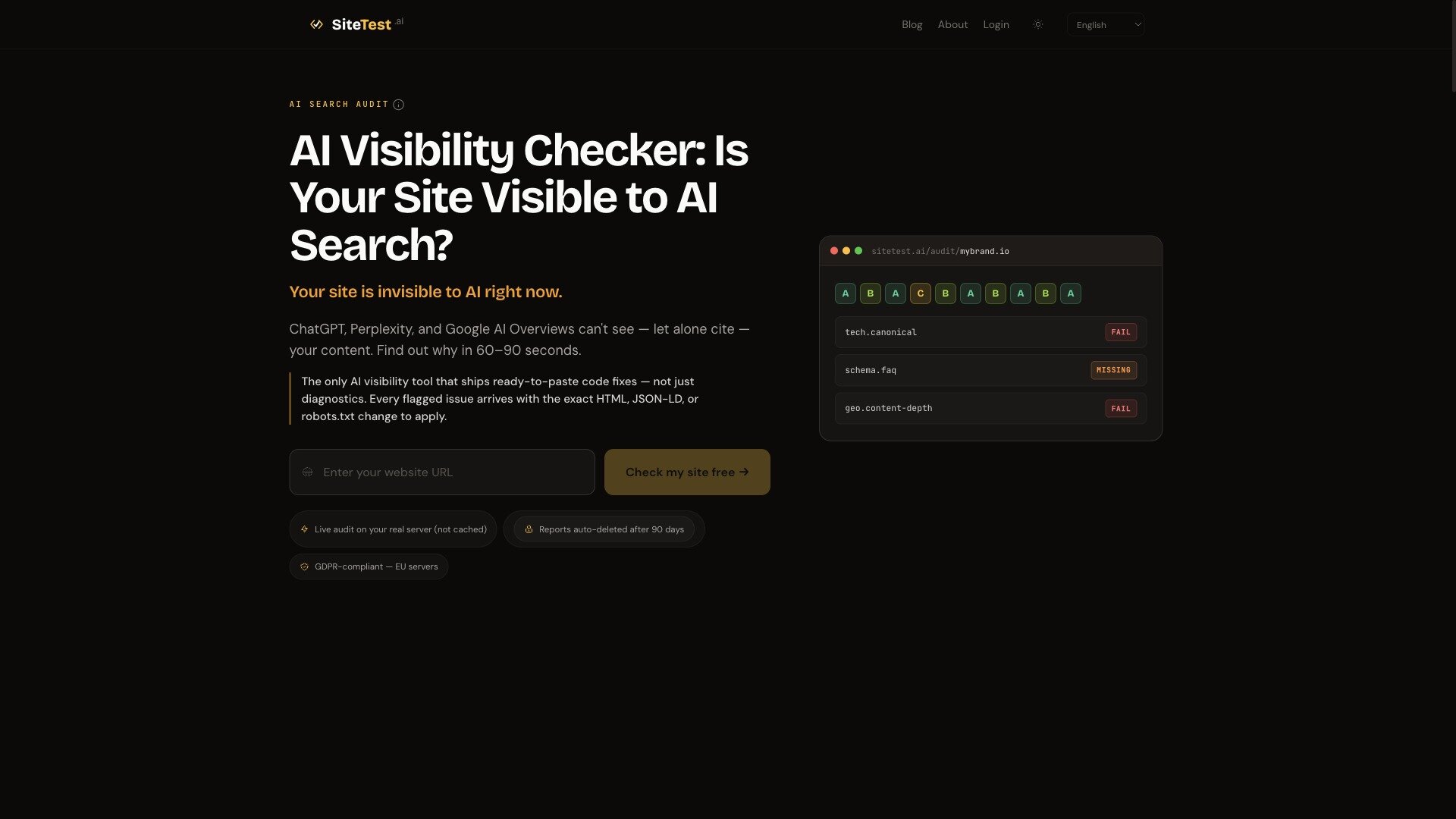
SiteTest.ai launches a free AI Visibility Checker for ChatGPT, Perplexity & Gemini
New free tool sitetest.ai runs a 168-point GEO audit, probing GPTBot, PerplexityBot and Google-Extended on your real server. Per-engine A–F grade plus copy-paste code fixes.

OpenClaw Developer Achieves AI Agent Breakthroughs with Uber and Restaurant Booking Automation
An OpenClaw developer has successfully created AI agents that autonomously complete Uber ride bookings and restaurant reservations on real websites, overcoming bot detection and CAPTCHAs using a stack with stealth browsers, residential proxies, and CAPTCHA solving.

Depct tool collects runtime data to help Claude debug production issues
Depct is a tool that collects runtime instrumentation from Node.js apps, builds graphs from the data, and feeds it to Claude via AWS Bedrock to help debug intermittent production failures. It also generates architecture diagrams and dependency maps from runtime behavior.

Engram Memory SDK: Graph-Based Memory for AI Agents with Local Models
Engram Memory SDK is an open-source graph memory system for AI agents that works with local models via LiteLLM. It requires only one LLM call for ingestion, then uses vector search and graph traversal for recall with zero ongoing LLM costs.