Pi Coding Agent with Qwen 35B Q2: Using Filesystem as External Memory and Enforcing Context Guards

A Reddit user shared their approach to agentic coding with local LLMs, built on Pi coding agent with Qwen 35B (Q2_K_XL quant via LM Studio). The core insight: treat the LLM as a logic processor, not a context database. The implementation enforces strict guards at the API boundary — the model cannot bypass them.
Key constraints enforced by the system
- Write/edit limit: Rejects any output over 100 lines. Model must write a skeleton first, then fill in one section at a time. If it tries to dump a full file, the call is blocked with instructions to split the work.
- Thinking block cap: If the model's reasoning exceeds 2000 chars, it receives a correction to write conclusions to disk and move on.
- Context monitor: At 65% context usage, the model is told to write its state to files. At 80%, everything stops — the model writes its 'brain' to disk while still coherent.
- Persistent output: If the model gives a long answer without writing a file, it's instructed to save findings to a step file. Nothing stays only in context.
External brain structure
The system uses .think/ and .plan/ directories as the model's external memory. Every step, decision, and finding is written to a file. When context compresses, the model reads its own notes back. The session purpose is saved separately to _purpose.md and re-injected after context compression, preserving the original goal.
Knowledge distillation
A /distill command crawls a codebase, builds an import graph, topologically sorts files, and has the model summarize them one per turn into a knowledge base. The manifest is split into pages of 50 files to avoid consuming the whole context. Users can drop files like svelte5-gotchas.md or astro-gotchas.md into a knowledge folder; an isolated LLM call selects which ones are relevant to the current task, and only the content gets injected into the main conversation.
Real-world result
The user asked the model to build a Three.js plane flying game. The first attempt tried to write 652 lines in one call — the guard rejected it. The model replanned, wrote a skeleton, then filled in features one edit at a time. The final result was a working game with 3D plane model, obstacles, HUD, minimap, and start/game over screens — all at Q2 quant.
The full setup runs at Q2_K_XL quantization as the floor; the user notes Q4 or Q8 should yield better results. The code is available on GitHub: github.com/Kodrack/Pi-forge.
📖 Read the full source: r/LocalLLaMA
👀 See Also
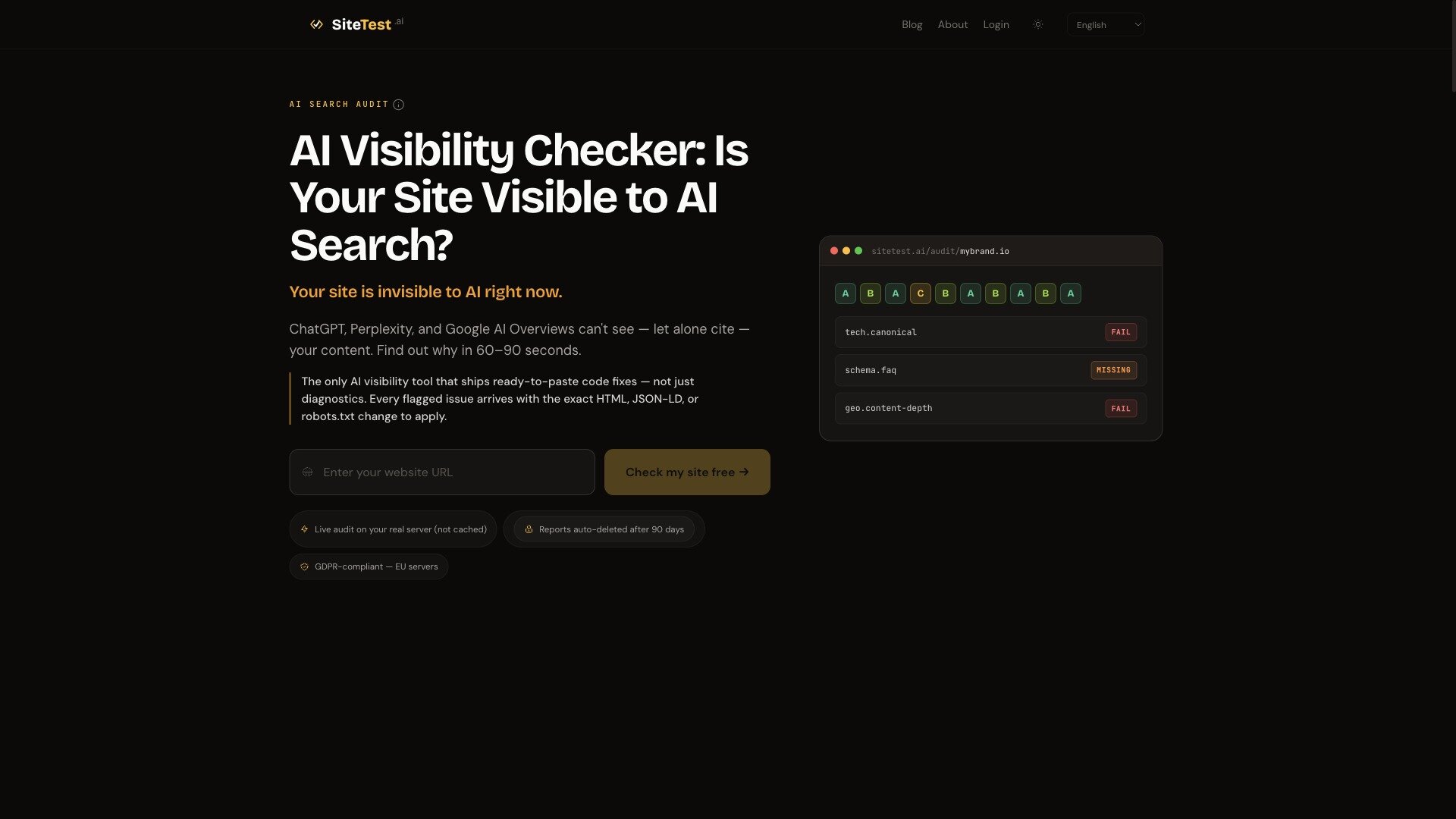
SiteTest.ai launches a free AI Visibility Checker for ChatGPT, Perplexity & Gemini
New free tool sitetest.ai runs a 168-point GEO audit, probing GPTBot, PerplexityBot and Google-Extended on your real server. Per-engine A–F grade plus copy-paste code fixes.

CC-Wiki: Turn Claude Code Sessions into a Shareable Quartz Knowledge Base
CC-Wiki converts your ~/.claude session history into a Quartz-based knowledge base. One command installs it; running /cc-wiki inside a Claude Code session packages the conversation.

EvalShift: Open-source CLI for detecting LLM regressions during model migration
EvalShift is an MIT-licensed Python CLI that compares source vs target LLM outputs across prompts, agents, and tool-calling workflows, generating a local HTML regression report.

Nakkas MCP Server Generates Animated SVGs from AI Descriptions
Nakkas is an MCP server where AI constructs complete animated SVG configurations from descriptions, rendering clean animated SVGs with shapes, gradients, animations, and filters. It supports parametric curves, 15 filter presets, CSS @keyframes and SMIL animations, and works anywhere SVG renders.